This post is the 4th in a series on serverless computing (see Part 1, Part 2, and Part 3) and will focus on the differences between serverless architectures and the more widely known Platform-as-a-Service (PaaS) and Extract-Transform-Load (ETL) architectures. If you are unsure about what is serverless computing, I strongly encourage you to go back to the earlier parts of the series to learn about the definition and to review concrete examples of microflows, which are applications based on serverless architecture. This post will also use the applications developed previously to illustrate a number of serverless architecture patterns.

How's serverless different?
Serverless and cloud. At a surface, the promise of serverless computing sounds similar to the original promise of cloud computing, namely helping developers to abstract away from servers, focus on writing code, avoid issues related to under/over provisioning of capacity, operating system patches, and so on. So what's new in serverless computing? To answer this question, it is important to remember that cloud computing defines three service models: Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS). Since serverless fits the definition of a PaaS[1], it offers many of the same benefits. However, unlike Cloud Foundry, OpenShift, Heroku, and other traditional PaaSes focused on supporting long running applications and services, serverless frameworks offer a new kind of a platform for running short lived processes and functions, also called microflows.
The distinction between the long running processes and microflows is subtle but important. When started, long running processes wait for an input, execute some code when an input is received, and then continue waiting. In contrast, microflows are started once an input is received, execute some code, and are terminated by the platform after the code in the microflow finishes executing. One way to describe microflows is to say that they are reactive, in the sense that they react to incoming requests and release resources after finishing work.
Serverless and microservices. Today, an increasing number of cloud based applications that are built to run on PaaSes follow a cloud native, microservices architecture[2]. Unlike microflows, microservices are long running processes designed to continuously require server capacity (see microservices deployment patterns[3]) while waiting for a request.
For example, a microservice deployed to a container based PaaS (e.g. Cloud Foundry) consumes memory and some fraction of the CPU even when not servicing requests. In most public cloud PaaSes, this continuous claim on CPU and memory resources directly translates to account charges. Further, microservices implementations may have memory leak bugs that result in increasing memory usage depending on how long a microservice has been running and how many requests it serviced. In contrast, microflows are designed to be launched on demand, upon the arrival of a specific type of a request to the PaaS hosting the microflow. After the code in the microflow finishes executing, the PaaS is responsible for releasing any resources allocated to the microflow during runtime, including memory. Although in practice the hosting PaaS may not fully release its memory resources to preserve a reusable, "hot" copy of a microflow for better performance, the PaaS can prevent runaway memory leaks by monitoring its memory usage and restarting the microflow.
Microflows naturally compliment microservices by providing means for microservices to communicate asynchronously as well as to execute one-off tasks, batch jobs, and other operations described later in this post based on serverless architecture patterns.
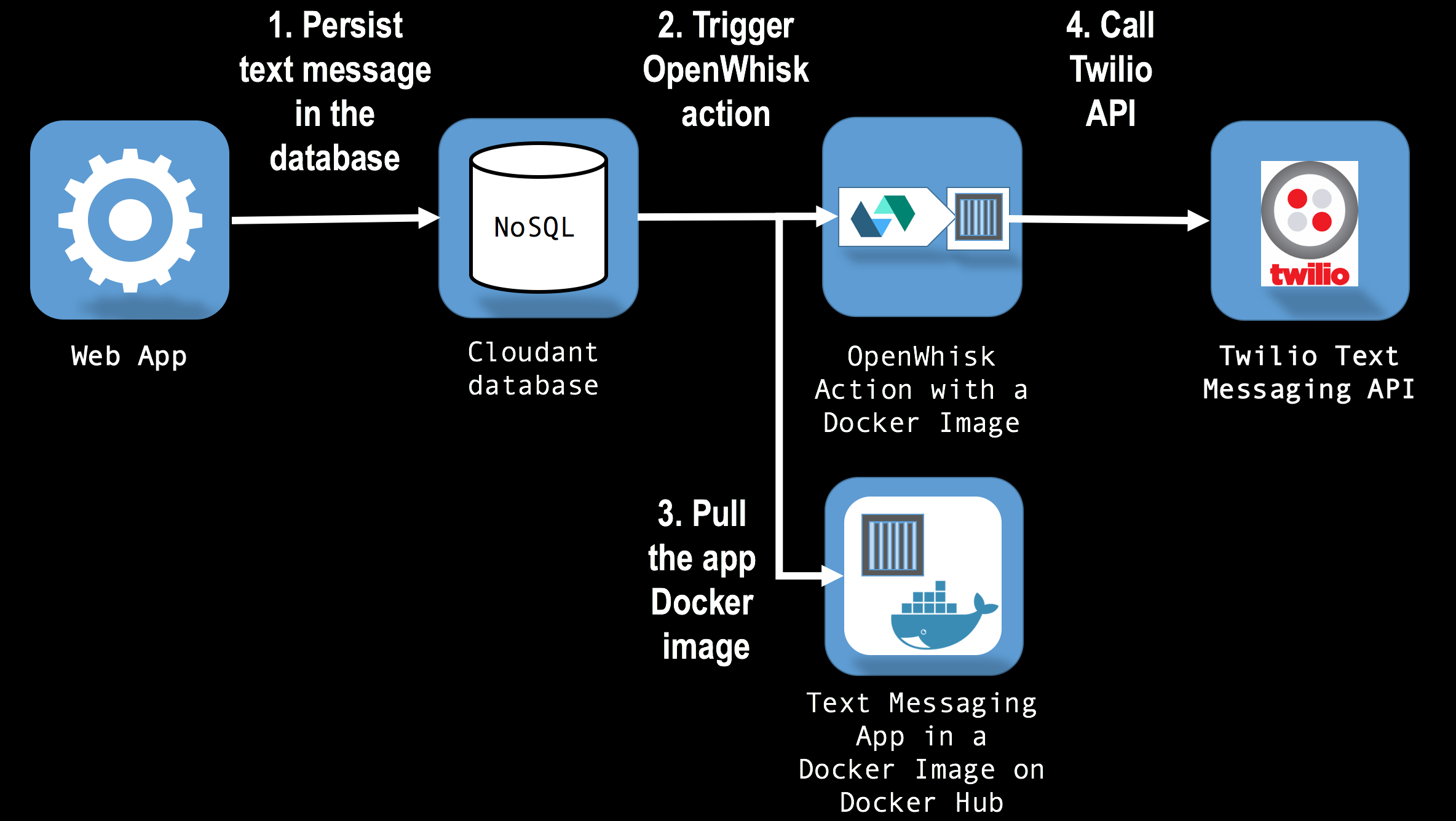
Serverless and ETL. Some may argue that serverless architecture is a new buzzword for the well known Extract Transform Load (ETL) technologies. The two are related, in fact, AWS advertises its serverless computing service, Lambda, as a solution for ETL-type of problems. However, unlike microflows, ETL applications are implicitly about data: they focus on a variety of data specific tasks, like import, filtering, sorting, transformations, and persistence. Serverless applications are broader in scope: they can extract, transform, and load data (see Part 3), but they are not limited to these operations. In practice, microflows (serverless applications), are as much about data operations as they are about calling services to execute operations like sending a text message (see Part 1 and Part 2) or changing temperature on an Internet-of-Things enabled thermostat. In short, serverless architecture patterns are not the same as ETL patterns.
Serverless architecture patterns
The following is a non-exhaustive and a non-mutually exclusive list of serverless computing patterns. The patterns are composable, in the sense that a serverless application may implement just one of the patterns, as in the examples in Part 1 and Part 2, or alternatively an application may be based on any number of the patterns, as in the example in Part 3.
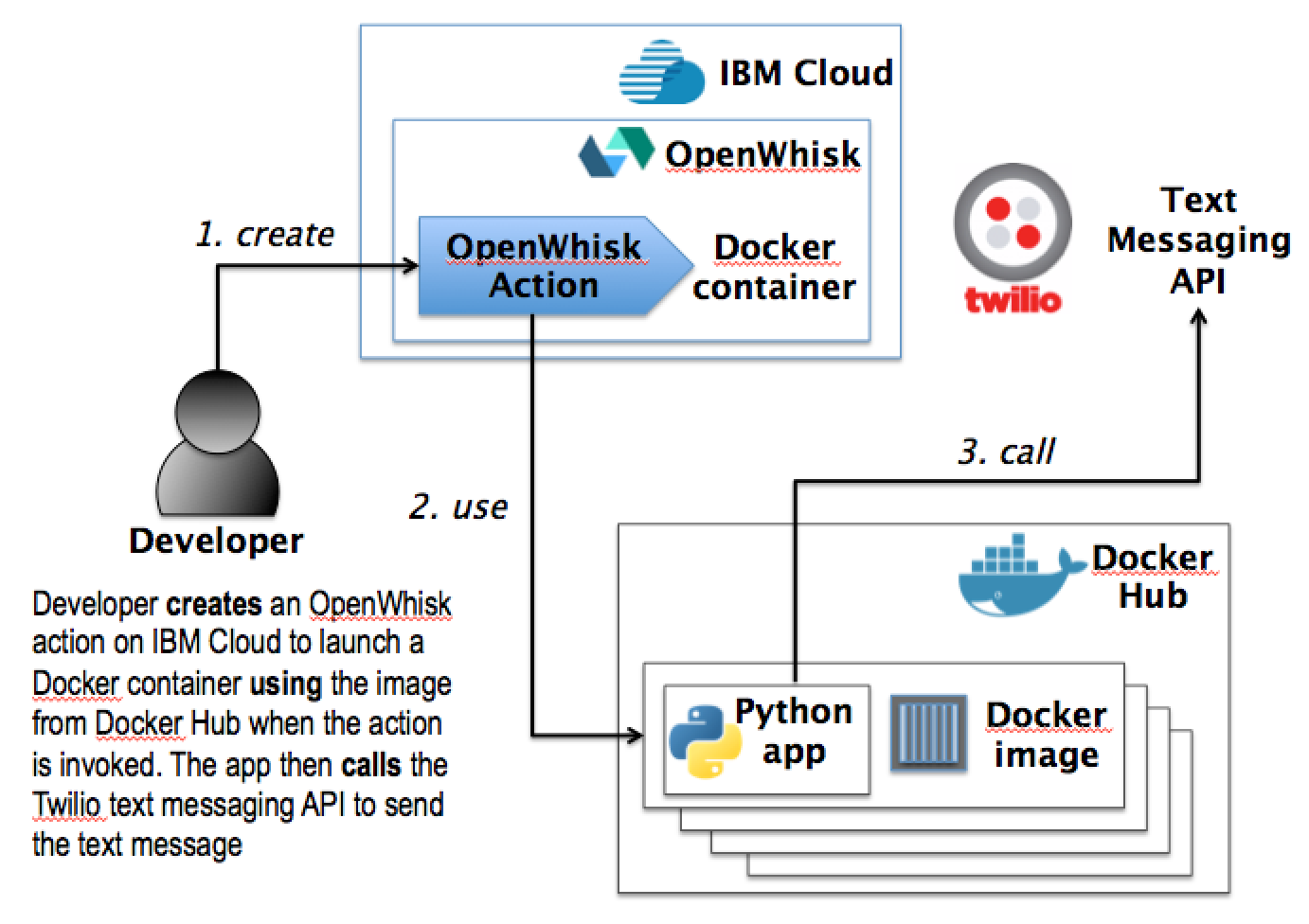
The command pattern describes serverless computing applications designed to orchestrate service requests to one or more services. The requests, which may be handled by microservices, can target a spectrum ranging from business services that can send text messages to customers to application services, such as those that handle webhook calls, and to infrastructure services, for example those responsible for provisioning additional virtual servers to deploy an application.
The enrich pattern is described in terms of the V's framework popularized by Gartner and IT vendors to describe qualities of Big Data[4]. The framework provides a convenient way to describe the different features of the serverless computing applications (microflows) that are focused on data processing. The enrich pattern facilitates increase in the Value of the microflow's input data by performing one or more of the following:
- improving data Veracity, by verifying or validating the data
- increasing the Volume of the data by augmenting it with additional, relevant data
- changing the Variety of the data by transforming or transcoding it
- accelerating the Velocity of the data by splitting it into chunks and forwarding the chunks, in parallel, to other services
The persist pattern describes applications that more closely resemble the traditional ETL apps than is the case with the other two patterns. When a microflow is based solely on this pattern, the application acts as an adapter or a router, transforming input data arriving to the microflow's service endpoint into records in one or more external data stores, which can be relational databases, NoSQL databases, or distributed in-memory caches. However, as illustrated by the example in Part 3, applications use this pattern in conjuction with other patterns, processing input data through enrich or command patterns, and then persisting the data to a data store.